
يتمتع الذكاء الاصطناعي والبيانات الضخمة بالقدرة على إيجاد حلول للمشاكل العالمية مع إعطاء الأولوية للقضايا المحلية وتحويل العالم بعدة طرق عميقة. يوفر الذكاء الاصطناعي الحلول للجميع - وفي جميع الأماكن ، من المنزل إلى أماكن العمل. أجهزة الكمبيوتر المزودة بتقنية الذكاء الاصطناعي تعلم آلة التدريب ، يمكنه محاكاة السلوك الذكي والمحادثات بطريقة آلية ولكنها مخصصة.
ومع ذلك ، يواجه الذكاء الاصطناعي مشكلة في الدمج وغالبًا ما يكون متحيزًا. لحسن الحظ ، التركيز على أخلاقيات الذكاء الاصطناعي يمكن أن تبشر بإمكانيات أحدث من حيث التنويع والشمول من خلال القضاء على التحيز اللاواعي من خلال بيانات التدريب المتنوعة.
أهمية التنوع في بيانات التدريب على الذكاء الاصطناعي
 يرتبط تنوع وجودة بيانات التدريب لأن أحدهما يؤثر على الآخر ويؤثر على نتيجة حل الذكاء الاصطناعي. يعتمد نجاح حل الذكاء الاصطناعي على بيانات متنوعة يتم تدريبه عليه. يمنع تنوع البيانات الذكاء الاصطناعي من التخصيص - بمعنى أن النموذج يؤدي فقط أو يتعلم من البيانات المستخدمة في التدريب. مع فرط التجهيز ، لا يمكن لنموذج الذكاء الاصطناعي تقديم نتائج عند اختباره على البيانات غير المستخدمة في التدريب.
يرتبط تنوع وجودة بيانات التدريب لأن أحدهما يؤثر على الآخر ويؤثر على نتيجة حل الذكاء الاصطناعي. يعتمد نجاح حل الذكاء الاصطناعي على بيانات متنوعة يتم تدريبه عليه. يمنع تنوع البيانات الذكاء الاصطناعي من التخصيص - بمعنى أن النموذج يؤدي فقط أو يتعلم من البيانات المستخدمة في التدريب. مع فرط التجهيز ، لا يمكن لنموذج الذكاء الاصطناعي تقديم نتائج عند اختباره على البيانات غير المستخدمة في التدريب.
الوضع الحالي لتدريب الذكاء الاصطناعي البيانات
قد يؤدي عدم المساواة أو عدم وجود تنوع في البيانات إلى حلول ذكاء اصطناعي غير عادلة وغير أخلاقية وغير شاملة يمكن أن تعمق التمييز. ولكن كيف ولماذا يرتبط التنوع في البيانات بحلول الذكاء الاصطناعي؟
التمثيل غير المتكافئ لجميع الفئات يؤدي إلى خطأ في التعرف على الوجوه - ومن الأمثلة المهمة على ذلك صور Google التي صنفت الزوجين السود على أنهما "غوريلا". وتحث Meta المستخدم الذي يشاهد مقطع فيديو لرجال سود عما إذا كان المستخدم يرغب في "متابعة مشاهدة مقاطع فيديو عن الرئيسيات".
على سبيل المثال ، قد يؤدي التصنيف غير الدقيق أو غير المناسب للأقليات العرقية أو العرقية ، خاصة في روبوتات المحادثة ، إلى التحيز في أنظمة التدريب على الذكاء الاصطناعي. وفقًا لتقرير 2019 حول أنظمة التمييز - الجنس والعرق والقوة في الذكاء الاصطناعيأكثر من 80٪ من معلمي الذكاء الاصطناعي هم من الرجال ؛ تشكل باحثات الذكاء الاصطناعي في الفيسبوك 15٪ فقط و 10٪ على جوجل.
تأثير بيانات التدريب المتنوعة على أداء الذكاء الاصطناعي
 يمكن أن يؤدي استبعاد مجموعات ومجتمعات محددة من تمثيل البيانات إلى خوارزميات منحرفة.
يمكن أن يؤدي استبعاد مجموعات ومجتمعات محددة من تمثيل البيانات إلى خوارزميات منحرفة.
غالبًا ما يتم إدخال تحيز البيانات عن طريق الخطأ في أنظمة البيانات - عن طريق نقص أخذ العينات من أعراق أو مجموعات معينة. عندما يتم تدريب أنظمة التعرف على الوجه على وجوه متنوعة ، فإنها تساعد النموذج على تحديد ميزات معينة ، مثل موضع أعضاء الوجه وتغيرات الألوان.
نتيجة أخرى لوجود تردد غير متوازن للعلامات هي أن النظام قد يعتبر الأقلية حالة شاذة عند الضغط عليها لإنتاج مخرجات في غضون فترة زمنية قصيرة.
تحقيق التنوع في بيانات التدريب على الذكاء الاصطناعي
على الجانب الآخر ، يعد إنشاء مجموعة بيانات متنوعة تحديًا أيضًا. قد يؤدي النقص الهائل في البيانات حول فئات معينة إلى نقص التمثيل. يمكن التخفيف من حدته من خلال جعل فرق مطوري الذكاء الاصطناعي أكثر تنوعًا فيما يتعلق بالمهارات والعرق والعرق والجنس والانضباط وغير ذلك. علاوة على ذلك ، فإن الطريقة المثلى لمعالجة مشاكل تنوع البيانات في الذكاء الاصطناعي هي مواجهتها من البداية بدلاً من محاولة إصلاح ما تم إنجازه - غرس التنوع في مرحلة جمع البيانات وتنظيمها.
بغض النظر عن الضجيج حول الذكاء الاصطناعي ، فإنه لا يزال يعتمد على البيانات التي تم جمعها واختيارها وتدريبها من قبل البشر. سينعكس التحيز الفطري لدى البشر في البيانات التي تم جمعها من قبلهم ، وهذا التحيز اللاواعي يتسلل إلى نماذج ML أيضًا.
خطوات لجمع وتنظيم بيانات التدريب المتنوعة
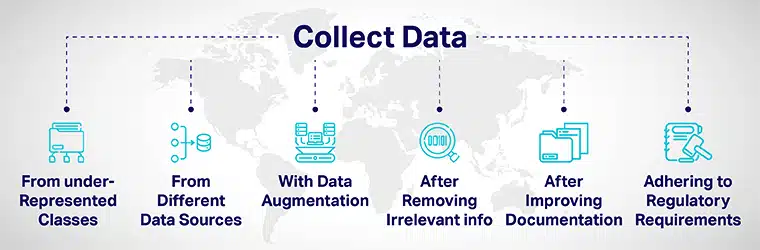
تنوع البيانات يمكن تحقيقه من خلال:
- قم بإضافة المزيد من البيانات بعناية من الفئات ذات التمثيل المنخفض وفضح النماذج الخاصة بك إلى نقاط بيانات متنوعة.
- من خلال جمع البيانات من مصادر البيانات المختلفة.
- عن طريق زيادة البيانات أو التلاعب بشكل مصطنع بمجموعات البيانات لزيادة / تضمين نقاط بيانات جديدة تختلف اختلافًا واضحًا عن نقاط البيانات الأصلية.
- عند تعيين المتقدمين لعملية تطوير الذكاء الاصطناعي ، قم بإزالة جميع المعلومات غير ذات الصلة بالوظيفة من التطبيق.
- تحسين الشفافية والمساءلة من خلال تحسين توثيق تطوير وتقييم النماذج.
- إدخال لوائح لبناء التنوع و الشمولية في الذكاء الاصطناعي أنظمة من مستوى الجذور. طورت حكومات مختلفة مبادئ توجيهية لضمان التنوع والتخفيف من تحيز الذكاء الاصطناعي الذي يمكن أن يؤدي إلى نتائج غير عادلة.
[اقرأ أيضًا: تعرف على المزيد حول عملية جمع بيانات التدريب على الذكاء الاصطناعي ]
وفي الختام
في الوقت الحالي ، يشارك عدد قليل فقط من شركات التكنولوجيا الكبرى ومراكز التعلم بشكل حصري في تطوير حلول الذكاء الاصطناعي. إن مساحات النخبة هذه غارقة في الإقصاء والتمييز والتحيز. ومع ذلك ، فهذه هي المساحات التي يتم فيها تطوير الذكاء الاصطناعي ، والمنطق الكامن وراء أنظمة الذكاء الاصطناعي المتقدمة هذه مليء بنفس التحيز والتمييز والإقصاء الذي تتحمله المجموعات غير الممثلة.
أثناء مناقشة التنوع وعدم التمييز ، من المهم استجواب الأشخاص الذين يستفيدون منهم وأولئك الذين يؤذونهم. يجب أن ننظر أيضًا إلى من يضعهم في وضع غير مؤات - من خلال فرض فكرة الشخص "الطبيعي" ، يمكن للذكاء الاصطناعي أن يعرض "الآخرين" للخطر.
لن تُظهر مناقشة التنوع في بيانات الذكاء الاصطناعي دون الاعتراف بعلاقات القوة والإنصاف والعدالة الصورة الأكبر. لفهم نطاق التنوع في بيانات التدريب على الذكاء الاصطناعي بشكل كامل وكيف يمكن للبشر والذكاء الاصطناعي معًا التخفيف من هذه الأزمة ، التواصل مع المهندسين في Shaip. لدينا مهندسون متنوعون للذكاء الاصطناعي يمكنهم توفير بيانات ديناميكية ومتنوعة لحلول الذكاء الاصطناعي الخاصة بك.


