
قطعت ميزة التعرف التلقائي على الكلام (ASR) شوطًا طويلاً. على الرغم من أنه تم اختراعه منذ فترة طويلة ، إلا أنه نادرًا ما يستخدمه أي شخص. ومع ذلك ، فقد تغير الوقت والتكنولوجيا الآن بشكل كبير. لقد تطور النسخ الصوتي بشكل كبير.
لقد عملت تقنيات مثل الذكاء الاصطناعي (AI) على دعم عملية الترجمة الصوتية إلى نص للحصول على نتائج سريعة ودقيقة. نتيجة لذلك ، زادت تطبيقاتها في العالم الحقيقي أيضًا ، مع تضمين بعض التطبيقات الشائعة مثل Tik Tok و Spotify و Zoom العملية في تطبيقات الأجهزة المحمولة الخاصة بهم.
لذلك دعونا نستكشف ASR ونكتشف سبب كونها واحدة من أكثر التقنيات شيوعًا في عام 2022.
ما هو الكلام الى نص؟
الكلام إلى نص هو تقنية محسّنة بالذكاء الاصطناعي تترجم الكلام البشري من شكل تناظري إلى شكل رقمي. علاوة على ذلك ، يتم نسخ النموذج الرقمي للبيانات التي تم جمعها في تنسيق نصي.
غالبًا ما يتم الخلط بين الكلام إلى نص والتعرف على الصوت والذي يختلف تمامًا عن هذه الطريقة. في التعرف على الصوت ، ينصب التركيز على تحديد أنماط الصوت للأشخاص ، بينما في هذه الطريقة ، يحاول النظام تحديد الكلمات التي يتم التحدث بها.
الأسماء الشائعة للكلام إلى نص
هذه التقنية المتقدمة للتعرف على الكلام شائعة أيضًا ويشار إليها بالأسماء:
- التعرف التلقائي على الكلام (ASR)
- التعرف على الكلام
- التعرف على الكلام من الكمبيوتر
- النسخ الصوتي
- قراءة الشاشة
فهم عمل التعرف التلقائي على الكلام
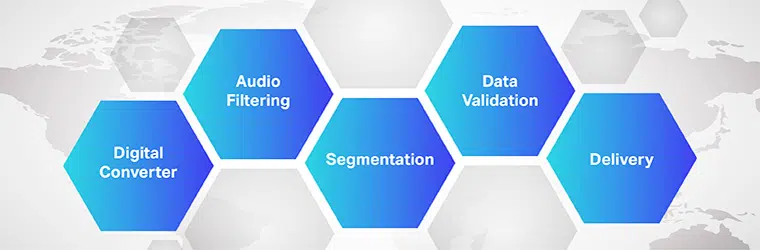
يعد عمل برامج الترجمة الصوتية إلى نص معقدًا وينطوي على تنفيذ خطوات متعددة. كما نعلم ، فإن تحويل الكلام إلى نص هو برنامج حصري مصمم لتحويل الملفات الصوتية إلى تنسيق نصي قابل للتحرير ؛ يفعل ذلك من خلال الاستفادة من التعرف على الصوت.
المعالجة:
- في البداية ، باستخدام المحول التناظري إلى الرقمي ، يطبق برنامج الكمبيوتر الخوارزميات اللغوية على البيانات المقدمة لتمييز الاهتزازات عن الإشارات السمعية.
- بعد ذلك ، يتم تصفية الأصوات ذات الصلة عن طريق قياس الموجات الصوتية.
- علاوة على ذلك ، يتم توزيع / تقسيم الأصوات إلى مئات أو أجزاء من الثواني ومطابقتها مع الصوتيات (وحدة صوت قابلة للقياس للتمييز بين كلمة وأخرى).
- يتم تشغيل الصوتيات من خلال نموذج رياضي لمقارنة البيانات الموجودة مع الكلمات والجمل والعبارات المعروفة.
- الإخراج في ملف نصي أو ملف صوتي قائم على الكمبيوتر.
[اقرأ أيضًا: نظرة عامة شاملة على التعرف التلقائي على الكلام]

ما هي استخدامات الكلام للنص؟
هناك العديد من استخدامات برامج التعرف التلقائي على الكلام ، مثل
- بحث المحتوى: لقد تحول معظمنا من كتابة الأحرف على هواتفنا إلى الضغط على زر حتى يتعرف البرنامج على صوتنا ويقدم النتائج المرجوة.
- خدمة العملاء: أصبحت الشات بوتس ومساعدو الذكاء الاصطناعي الذين يمكنهم توجيه العملاء من خلال الخطوات الأولية القليلة للعملية شائعين.
- الترجمة والشرح في الوقت الحقيقي: مع زيادة الوصول العالمي إلى المحتوى ، أصبحت ميزة التسميات التوضيحية المغلقة في الوقت الفعلي سوقًا بارزة وهامة ، مما دفع ASR إلى الأمام لاستخدامها.
- التوثيق الإلكتروني: بدأت العديد من الإدارات الإدارية في استخدام ASR لتحقيق أغراض التوثيق ، مما يؤدي إلى تحسين السرعة والكفاءة.
ما هي التحديات الرئيسية التي تواجه التعرف على الكلام؟
التعليق التوضيحي الصوتي لم تصل بعد إلى ذروة تطورها. لا يزال هناك العديد من التحديات التي يحاول المهندسون مواجهتها لجعل النظام فعالاً ، مثل
- السيطرة على اللهجات واللهجات.
- فهم سياق الجمل المنطوقة.
- فصل ضوضاء الخلفية لتضخيم جودة الإدخال.
- تحويل الكود إلى لغات مختلفة للمعالجة الفعالة.
- تحليل الإشارات المرئية المستخدمة في الكلام في حالة ملفات الفيديو.
النسخ الصوتية وتطوير الذكاء الاصطناعي لتحويل الكلام إلى نص
يتمثل التحدي الأكبر في برنامج التعرف التلقائي على الكلام في إنشاء مخرجاته بدقة 100٪. نظرًا لأن البيانات الأولية ديناميكية ولا يمكن تطبيق خوارزمية واحدة ، يتم شرح البيانات لتدريب الذكاء الاصطناعي على فهمها في السياق الصحيح.
لأداء هذه العملية ، يجب تنفيذ مهام محددة ، مثل:
 التعرف على الكيان المحدد (NER): NER هي عملية تحديد وتقسيم الكيانات المسماة المختلفة إلى فئات محددة.
التعرف على الكيان المحدد (NER): NER هي عملية تحديد وتقسيم الكيانات المسماة المختلفة إلى فئات محددة.- تحليل المشاعر والموضوع: يقوم البرنامج الذي يستخدم خوارزميات متعددة بإجراء تحليل المشاعر للبيانات المقدمة لتوفير نتائج خالية من الأخطاء.
 التعرف على الكيان المحدد (NER):
التعرف على الكيان المحدد (NER): - تحليل النية والمحادثة: يهدف اكتشاف النية إلى تدريب الذكاء الاصطناعي على التعرف على نية المتحدث. يتم استخدامه بشكل أساسي لإنشاء روبوتات محادثة مدعومة بالذكاء الاصطناعي.
وفي الختام
تعد تقنية تحويل الكلام إلى نص مرحلة رائعة في الوقت الحالي. مع وجود المزيد من الأجهزة الرقمية التي تتضمن البحث الصوتي ومساعدي التحكم في تطبيقاتهم ، فإن الطلب على نسخ الصوت من المقرر أن يرتفع. إذا كنت حريصًا على إضافة هذه الميزة الرائعة إلى تطبيقك ، فاتصل بخبراء جمع بيانات الكلام في Shaip لمعرفة التفاصيل الكاملة.


