

ما هي نماذج اللغات الكبيرة؟
نماذج اللغات الكبيرة (LLMs) هي أنظمة ذكاء اصطناعي (AI) متقدمة مصممة لمعالجة وفهم وإنشاء نص يشبه الإنسان. إنها تستند إلى تقنيات التعلم العميق ويتم تدريبها على مجموعات بيانات ضخمة ، وعادة ما تحتوي على مليارات الكلمات من مصادر متنوعة مثل المواقع الإلكترونية والكتب والمقالات. يمكّن هذا التدريب المكثف LLM من فهم الفروق الدقيقة في اللغة والقواعد والسياق وحتى بعض جوانب المعرفة العامة.
تستخدم بعض LLMs الشهيرة ، مثل GPT-3 الخاص بـ OpenAI ، نوعًا من الشبكات العصبية يسمى المحول ، والذي يسمح لهم بالتعامل مع المهام اللغوية المعقدة بكفاءة ملحوظة. يمكن لهذه النماذج أداء مجموعة واسعة من المهام ، مثل:
- الاجابة عن الاسئلة
- تلخيص النص
- ترجمة اللغات
- توليد المحتوى
- حتى الانخراط في محادثات تفاعلية مع المستخدمين
مع استمرار تطور LLM ، لديهم إمكانات كبيرة لتعزيز وأتمتة التطبيقات المختلفة عبر الصناعات ، من خدمة العملاء وإنشاء المحتوى إلى التعليم والبحث. ومع ذلك ، فإنها تثير أيضًا مخاوف أخلاقية ومجتمعية ، مثل السلوك المتحيز أو سوء الاستخدام ، والتي يجب معالجتها مع تقدم التكنولوجيا.

أمثلة شائعة لنماذج اللغة الكبيرة
فيما يلي بعض الأمثلة البارزة على LLM المستخدمة على نطاق واسع في قطاعات الصناعة المختلفة:
مصدر الصورة: نحو علم البيانات
كيف يتم تدريب نماذج LLM؟
يعد تدريب نماذج اللغة الكبيرة (LLMs) عملاً فذًا يتضمن عدة خطوات حاسمة. في ما يلي ملخص مبسط للعملية خطوة بخطوة:
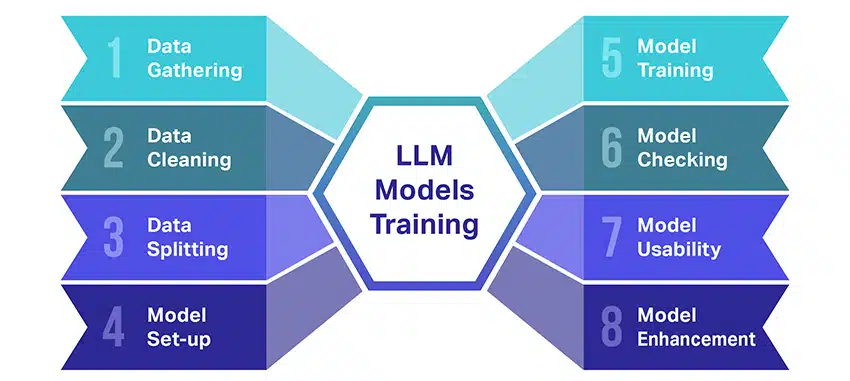
- جمع بيانات النص: يبدأ تدريب LLM بجمع كمية هائلة من البيانات النصية. يمكن أن تأتي هذه البيانات من الكتب أو مواقع الويب أو المقالات أو منصات الوسائط الاجتماعية. الهدف هو التقاط التنوع الغني للغة البشرية.
- تنظيف البيانات: ثم يتم ترتيب بيانات النص الخام في عملية تسمى المعالجة المسبقة. يتضمن ذلك مهام مثل إزالة الأحرف غير المرغوب فيها ، وتقسيم النص إلى أجزاء أصغر تسمى الرموز ، وتحويلها جميعًا إلى تنسيق يمكن للنموذج العمل به.
- تقسيم البيانات: بعد ذلك ، يتم تقسيم البيانات النظيفة إلى مجموعتين. سيتم استخدام مجموعة واحدة ، وهي بيانات التدريب ، لتدريب النموذج. المجموعة الأخرى ، بيانات التحقق ، سيتم استخدامها لاحقًا لاختبار أداء النموذج.
- إعداد النموذج: ثم يتم تحديد هيكل LLM ، المعروف باسم الهندسة المعمارية. يتضمن ذلك تحديد نوع الشبكة العصبية واتخاذ قرار بشأن المعلمات المختلفة ، مثل عدد الطبقات والوحدات المخفية داخل الشبكة.
- تدريب النموذج: التدريب الفعلي يبدأ الآن. يتعلم نموذج LLM من خلال النظر إلى بيانات التدريب ، وإجراء تنبؤات بناءً على ما تعلمه حتى الآن ، ثم تعديل معلماته الداخلية لتقليل الاختلاف بين تنبؤاته والبيانات الفعلية.
- فحص النموذج: يتم التحقق من تعلم نموذج LLM باستخدام بيانات التحقق من الصحة. يساعد هذا في معرفة مدى جودة أداء النموذج وتعديل إعدادات النموذج للحصول على أداء أفضل.
- استخدام النموذج: بعد التدريب والتقييم ، يكون نموذج LLM جاهزًا للاستخدام. يمكن الآن دمجها في التطبيقات أو الأنظمة حيث سيتم إنشاء نص بناءً على المدخلات الجديدة التي يتم تقديمها.
- تحسين النموذج: أخيرًا ، هناك دائمًا مجال للتحسين. يمكن تحسين نموذج LLM بمرور الوقت ، باستخدام البيانات المحدثة أو ضبط الإعدادات بناءً على التعليقات والاستخدام في العالم الحقيقي.
تذكر أن هذه العملية تتطلب موارد حسابية كبيرة ، مثل وحدات المعالجة القوية والتخزين الكبير ، فضلاً عن المعرفة المتخصصة في التعلم الآلي. لهذا السبب يتم إجراؤها عادةً بواسطة مؤسسات بحثية مخصصة أو شركات تتمتع بإمكانية الوصول إلى البنية التحتية والخبرة اللازمة.
هل تعتمد LLM على التعلم الخاضع للإشراف أو غير الخاضع للإشراف؟
عادة ما يتم تدريب النماذج اللغوية الكبيرة باستخدام طريقة تسمى التعلم تحت الإشراف. بعبارات بسيطة ، هذا يعني أنهم يتعلمون من الأمثلة التي توضح لهم الإجابات الصحيحة.
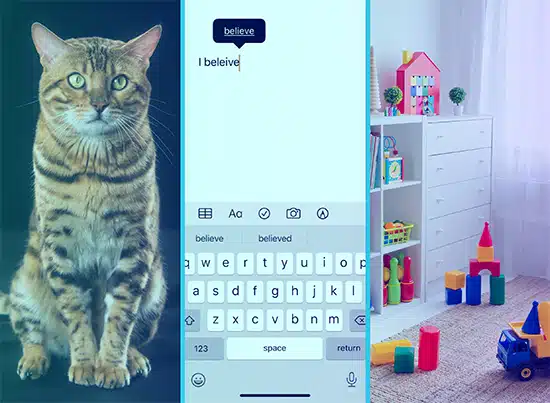 تخيل أنك تعلم كلمات طفل من خلال عرض الصور عليهم. تظهر لهم صورة قطة وتقول "قطة" ، ويتعلمون ربط تلك الصورة بالكلمة. هذه هي الطريقة التي يعمل بها التعلم الخاضع للإشراف. يُعطى النموذج الكثير من النصوص ("الصور") والمخرجات المقابلة ("الكلمات") ، ويتعلم مطابقتها.
تخيل أنك تعلم كلمات طفل من خلال عرض الصور عليهم. تظهر لهم صورة قطة وتقول "قطة" ، ويتعلمون ربط تلك الصورة بالكلمة. هذه هي الطريقة التي يعمل بها التعلم الخاضع للإشراف. يُعطى النموذج الكثير من النصوص ("الصور") والمخرجات المقابلة ("الكلمات") ، ويتعلم مطابقتها.
لذلك ، إذا قمت بإطعام جملة LLM ، فإنها تحاول التنبؤ بالكلمة أو العبارة التالية بناءً على ما تعلمته من الأمثلة. بهذه الطريقة ، تتعلم كيفية إنشاء نص يكون منطقيًا ويناسب السياق.
ومع ذلك ، في بعض الأحيان تستخدم LLM أيضًا القليل من التعلم غير الخاضع للإشراف. يشبه هذا السماح للطفل باستكشاف غرفة مليئة بالألعاب المختلفة والتعرف عليها بمفرده. يبحث النموذج في البيانات غير المسماة ، وأنماط التعلم ، والهياكل دون أن يتم إخباره بالإجابات "الصحيحة".
يستخدم التعلم الخاضع للإشراف البيانات التي تم تصنيفها بالمدخلات والمخرجات ، على عكس التعلم غير الخاضع للإشراف ، والذي لا يستخدم بيانات الإخراج المصنفة.
باختصار ، يتم تدريب LLM بشكل أساسي باستخدام التعلم الخاضع للإشراف ، ولكن يمكنهم أيضًا استخدام التعلم غير الخاضع للإشراف لتعزيز قدراتهم ، مثل التحليل الاستكشافي وتقليل الأبعاد.
ما هو حجم البيانات (بالجيجابايت) اللازمة لتدريب نموذج لغوي كبير؟
عالم إمكانيات التعرف على بيانات الكلام والتطبيقات الصوتية هائل ، ويتم استخدامها في العديد من الصناعات لعدد كبير من التطبيقات.
إن تدريب نموذج لغوي كبير ليس عملية تناسب الجميع ، خاصة عندما يتعلق الأمر بالبيانات المطلوبة. يعتمد ذلك على مجموعة من الأشياء:
- تصميم النموذج.
- ما هي الوظيفة التي يجب أن تقوم بها؟
- نوع البيانات التي تستخدمها.
- ما مدى جودة الأداء الذي تريده؟
ومع ذلك ، يتطلب تدريب LLM عادةً قدرًا هائلاً من البيانات النصية. لكن ما مدى ضخامة ما نتحدث عنه؟ حسنًا ، فكر بطريقة تتجاوز الجيجابايت. عادة ما ننظر إلى تيرابايت (TB) أو حتى بيتابايت (PB) من البيانات.
ضع في اعتبارك GPT-3 ، أحد أكبر LLMs الموجودة. يتم تدريبه على 570 جيجا بايت من البيانات النصية. قد تحتاج LLM الأصغر حجمًا إلى أقل - ربما من 10 إلى 20 جيجابايت أو حتى 1 جيجابايت من جيجابايت - لكنها لا تزال كثيرة.

لكن الأمر لا يتعلق فقط بحجم البيانات. الجودة مهمة أيضًا. يجب أن تكون البيانات نظيفة ومتنوعة لمساعدة النموذج على التعلم بشكل فعال. ولا يمكنك أن تنسى الأجزاء الرئيسية الأخرى من اللغز ، مثل قوة الحوسبة التي تحتاجها ، والخوارزميات التي تستخدمها للتدريب ، وإعدادات الأجهزة التي لديك. تلعب كل هذه العوامل دورًا كبيرًا في تدريب ماجستير.
ظهور نماذج اللغة الكبيرة: سبب أهميتها
لم تعد LLM مجرد مفهوم أو تجربة. إنهم يلعبون بشكل متزايد دورًا مهمًا في المشهد الرقمي لدينا. ولكن لماذا يحدث هذا؟ ما الذي يجعل هذه LLM مهمة جدًا؟ دعنا نتعمق في بعض العوامل الرئيسية.
التمكن في تقليد النص البشري
لقد غيرت LLM الطريقة التي نتعامل بها مع المهام القائمة على اللغة. تم تصميم هذه النماذج باستخدام خوارزميات قوية للتعلم الآلي ، وهي مجهزة بالقدرة على فهم الفروق الدقيقة في اللغة البشرية ، بما في ذلك السياق والعاطفة وحتى السخرية ، إلى حد ما. هذه القدرة على تقليد اللغة البشرية ليست مجرد حداثة ، بل لها آثار مهمة.
يمكن لقدرات إنشاء النصوص المتقدمة لـ LLMs تحسين كل شيء من إنشاء المحتوى إلى تفاعلات خدمة العملاء.
تخيل أن تكون قادرًا على طرح سؤال معقد على مساعد رقمي والحصول على إجابة ليست منطقية فحسب ، ولكنها أيضًا متماسكة وذات صلة ويتم تقديمها بنبرة محادثة. هذا ما تمكّنه LLM. إنها تغذي تفاعلًا أكثر سهولة وجاذبية بين الإنسان والآلة ، وتثري تجارب المستخدم ، وتضفي الطابع الديمقراطي على الوصول إلى المعلومات.
قوة حوسبة ميسورة التكلفة
لم يكن ظهور LLM ممكنًا بدون تطورات موازية في مجال الحوسبة. وبشكل أكثر تحديدًا ، لعبت دمقرطة الموارد الحسابية دورًا مهمًا في تطور واعتماد LLM.
توفر الأنظمة الأساسية القائمة على السحابة وصولاً غير مسبوق إلى موارد الحوسبة عالية الأداء. بهذه الطريقة ، يمكن حتى للمنظمات الصغيرة والباحثين المستقلين تدريب نماذج التعلم الآلي المتطورة.
علاوة على ذلك ، فإن التحسينات في وحدات المعالجة (مثل GPUs و TPU) ، جنبًا إلى جنب مع ظهور الحوسبة الموزعة ، جعلت من الممكن تدريب النماذج التي تحتوي على مليارات من المعلمات. تتيح إمكانية الوصول المتزايدة لقوة الحوسبة نمو ونجاح LLM ، مما يؤدي إلى المزيد من الابتكار والتطبيقات في هذا المجال.
تغيير تفضيلات المستهلك
لا يرغب المستهلكون اليوم في الحصول على إجابات فحسب ؛ يريدون تفاعلات جذابة ومترابطة. مع نمو المزيد من الناس باستخدام التكنولوجيا الرقمية ، من الواضح أن الحاجة إلى التكنولوجيا التي تبدو أكثر طبيعية وشبيهة بالبشر آخذة في الازدياد. توفر LLM فرصة لا مثيل لها لتلبية هذه التوقعات. من خلال إنشاء نص يشبه الإنسان ، يمكن لهذه النماذج إنشاء تجارب رقمية جذابة وديناميكية ، والتي يمكن أن تزيد من رضا المستخدم وولائه. سواء أكانت روبوتات الدردشة بالذكاء الاصطناعي تقدم خدمة العملاء أو المساعدين الصوتيين الذين يقدمون تحديثات الأخبار ، فإن LLMs تبشر بعصر الذكاء الاصطناعي الذي يفهمنا بشكل أفضل.
منجم الذهب غير المنظم للبيانات
تعد البيانات غير المنظمة ، مثل رسائل البريد الإلكتروني ومنشورات الوسائط الاجتماعية ومراجعات العملاء ، كنزًا دفينًا من الأفكار. يقدر أن انتهى 80% من بيانات المؤسسة غير منظمة وتتزايد بمعدل 55% كل سنة. هذه البيانات هي منجم ذهب للشركات إذا تم الاستدانة بها بشكل صحيح.
تلعب LLM دورًا هنا ، مع قدرتها على معالجة هذه البيانات وفهمها على نطاق واسع. يمكنهم التعامل مع مهام مثل تحليل المشاعر وتصنيف النص واستخراج المعلومات والمزيد ، وبالتالي توفير رؤى قيمة.
سواء أكان تحديد الاتجاهات من منشورات وسائل التواصل الاجتماعي أو قياس معنويات العملاء من المراجعات ، فإن LLMs تساعد الشركات على التنقل في كمية كبيرة من البيانات غير المهيكلة واتخاذ قرارات تعتمد على البيانات.
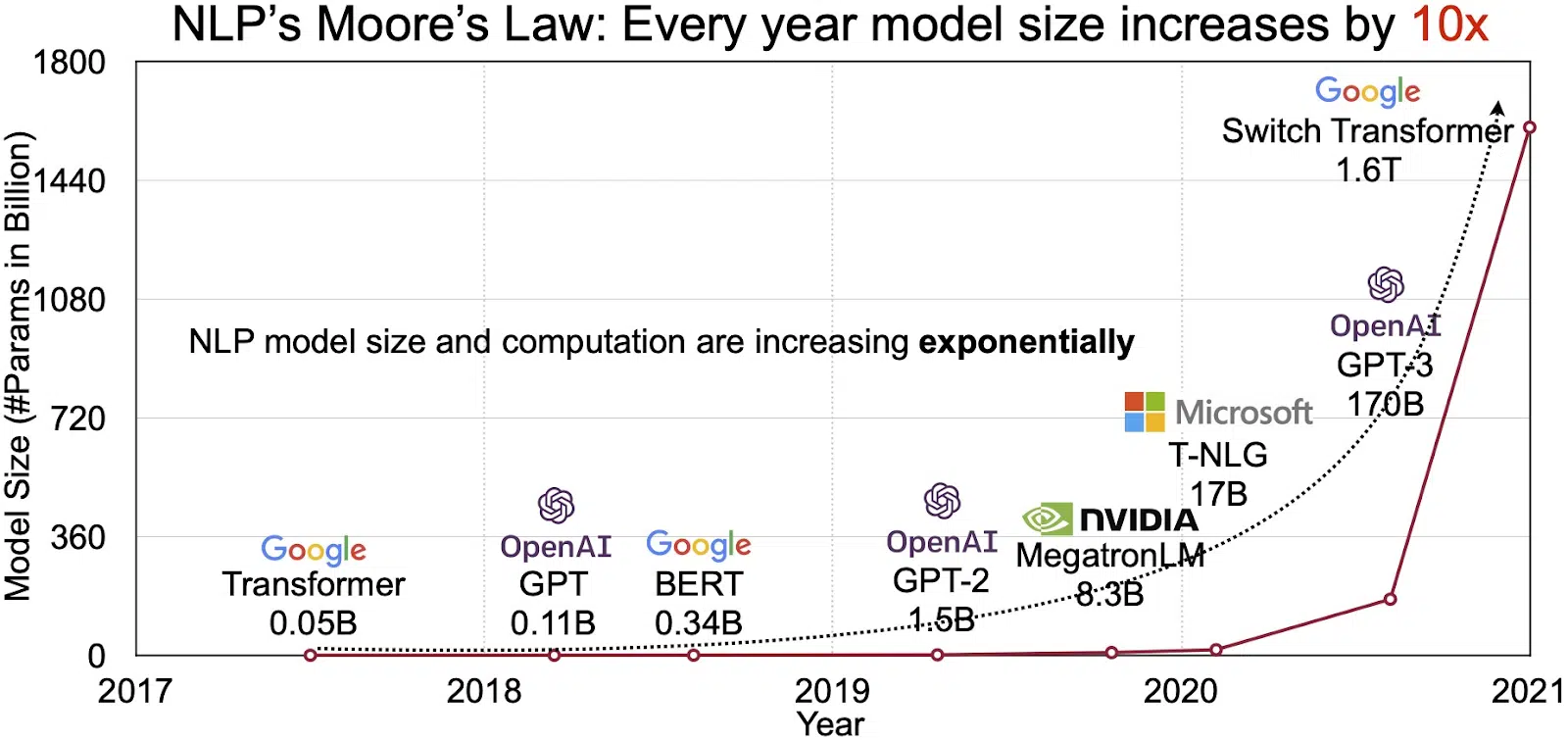
التوسع في سوق البرمجة اللغوية العصبية
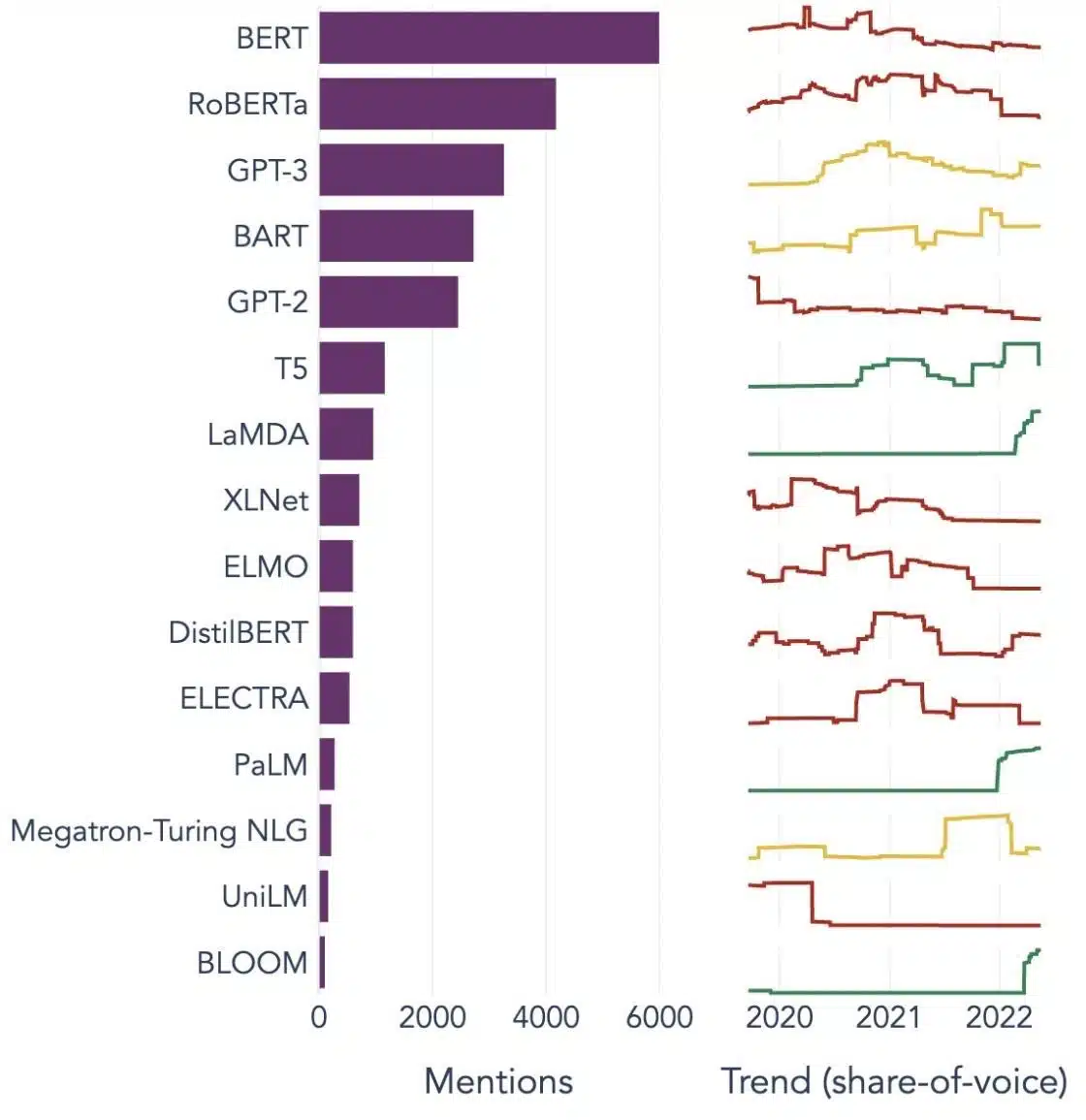
تنعكس إمكانات LLM في السوق سريع النمو لمعالجة اللغة الطبيعية (NLP). يتوقع المحللون أن يتوسع سوق البرمجة اللغوية العصبية من 11 مليار دولار في عام 2020 إلى أكثر من 35 مليار دولار بحلول عام 2026. لكن ليس حجم السوق فقط هو الذي يتوسع. النماذج نفسها تنمو أيضًا ، سواء من حيث الحجم المادي أو في عدد المعلمات التي تتعامل معها. يؤكد تطور LLM على مر السنين ، كما هو موضح في الشكل أدناه (مصدر الصورة: الرابط) ، على زيادة تعقيدها وقدرتها.
حالات الاستخدام الشائعة لنماذج اللغات الكبيرة
فيما يلي بعض حالات الاستخدام الأعلى والأكثر انتشارًا لـ LLM:
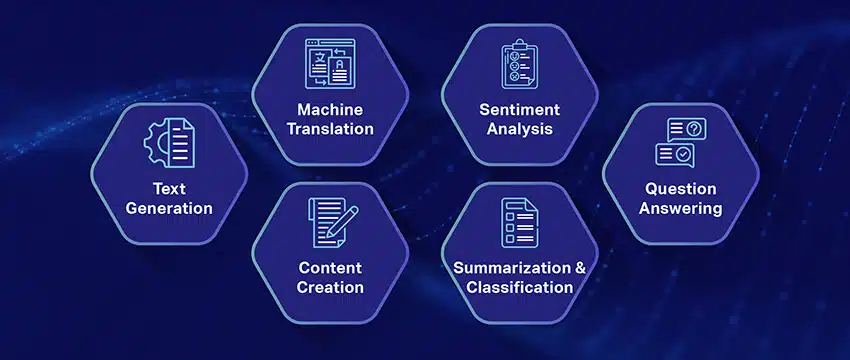
- توليد نص بلغة طبيعية: تجمع نماذج اللغات الكبيرة (LLMs) بين قوة الذكاء الاصطناعي واللغويات الحاسوبية لإنتاج نصوص بلغة طبيعية بشكل مستقل. يمكنهم تلبية احتياجات المستخدمين المتنوعة مثل كتابة المقالات أو صياغة الأغاني أو الانخراط في محادثات مع المستخدمين.
- الترجمة من خلال الآلات: يمكن استخدام LLMs بشكل فعال لترجمة النص بين أي زوج من اللغات. تستغل هذه النماذج خوارزميات التعلم العميق مثل الشبكات العصبية المتكررة لفهم البنية اللغوية لكل من اللغات المصدر والهدف ، وبالتالي تسهيل ترجمة النص المصدر إلى اللغة المطلوبة.
- صياغة المحتوى الأصلي: فتحت LLM سبلًا للآلات لإنشاء محتوى متماسك ومنطقي. يمكن استخدام هذا المحتوى لإنشاء منشورات مدونة ومقالات وأنواع أخرى من المحتوى. تستفيد النماذج من تجربتها العميقة في التعلم العميق لتنسيق المحتوى وبنيته بطريقة جديدة وسهلة الاستخدام.
- تحليل المشاعر: أحد التطبيقات المثيرة للاهتمام لنماذج اللغات الكبيرة هو تحليل المشاعر. في هذا ، يتم تدريب النموذج على التعرف على الحالات العاطفية والمشاعر الموجودة في النص المشروح وتصنيفها. يمكن للبرنامج تحديد المشاعر مثل الإيجابية والسلبية والحياد والمشاعر المعقدة الأخرى. يمكن أن يوفر ذلك رؤى قيمة حول ملاحظات العملاء ووجهات النظر حول المنتجات والخدمات المختلفة.
- فهم النص وتلخيصه وتصنيفه: تنشئ LLM بنية قابلة للتطبيق لبرمجيات الذكاء الاصطناعي لتفسير النص وسياقه. من خلال توجيه النموذج لفهم وفحص كميات هائلة من البيانات ، تمكن LLM نماذج الذكاء الاصطناعي من فهم وتلخيص وحتى تصنيف النص في أشكال وأنماط متنوعة.
- الاجابة عن الاسئلة: تزود نماذج اللغات الكبيرة أنظمة الإجابة على الأسئلة (QA) بالقدرة على الإدراك الدقيق والاستجابة لاستعلام اللغة الطبيعية للمستخدم. تشمل الأمثلة الشائعة لحالة الاستخدام هذه ChatGPT و BERT ، اللذان يفحصان سياق استعلام ويفحصان مجموعة كبيرة من النصوص لتقديم إجابات ذات صلة بأسئلة المستخدم.

وضع علامات على جزء من الكلام (POS)
يتم تمييز الكلمات في الجمل بوظائفها النحوية ، مثل الأفعال ، والأسماء ، والصفات ، وما إلى ذلك. تساعد هذه العملية النموذج في فهم القواعد والصلات بين الكلمات.

التعرف على الكيان المحدد (NER)
يتم تمييز الكيانات المسماة مثل المؤسسات والمواقع والأشخاص داخل جملة. يساعد هذا التمرين النموذج في تفسير المعاني الدلالية للكلمات والعبارات ويوفر إجابات أكثر دقة.

تحليل المشاعر
يتم تعيين تسميات المشاعر لبيانات النص مثل إيجابية أو محايدة أو سلبية ، مما يساعد النموذج على فهم الطبقة العاطفية للجمل. إنه مفيد بشكل خاص في الرد على الاستفسارات التي تنطوي على المشاعر والآراء.
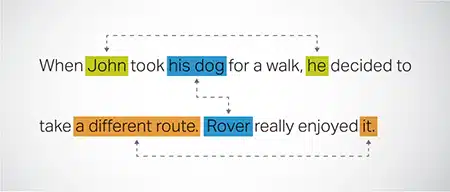
قرار Coreference
تحديد وحل الحالات التي تتم فيها الإشارة إلى نفس الكيان في أجزاء مختلفة من النص. تساعد هذه الخطوة النموذج على فهم سياق الجملة ، مما يؤدي إلى استجابات متماسكة.
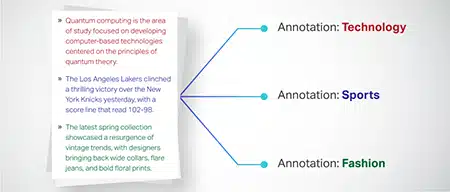
تصنيف النص
يتم تصنيف البيانات النصية إلى مجموعات محددة مسبقًا مثل مراجعات المنتجات أو المقالات الإخبارية. يساعد هذا النموذج في تمييز نوع النص أو موضوعه ، مما يؤدي إلى استجابات أكثر صلة بالموضوع.
عرض شيب
شيب تقدم مجموعة واسعة من الخدمات لمساعدة المؤسسات على إدارة بياناتها وتحليلها والاستفادة منها إلى أقصى حد.
تجريف البيانات عبر الويب
إحدى الخدمات الرئيسية التي تقدمها Shaip هي تجريف البيانات. يتضمن ذلك استخراج البيانات من عناوين URL الخاصة بالمجال. من خلال استخدام الأدوات والتقنيات المؤتمتة ، يمكن لـ Shaip استخراج كميات كبيرة من البيانات بسرعة وكفاءة من مواقع الويب المختلفة ، وأدلة المنتجات ، والوثائق الفنية ، والمنتديات عبر الإنترنت ، والمراجعات عبر الإنترنت ، وبيانات خدمة العملاء ، والوثائق التنظيمية الصناعية وما إلى ذلك. يمكن أن تكون هذه العملية لا تقدر بثمن بالنسبة للشركات عندما جمع البيانات ذات الصلة والمحددة من مصادر متعددة.

الترجمة الآلية
طوّر نماذج باستخدام مجموعات بيانات شاملة متعددة اللغات مقترنة بنسخ مقابلة لترجمة النص عبر لغات مختلفة. تساعد هذه العملية في تفكيك العقبات اللغوية وتعزيز إمكانية الوصول إلى المعلومات.
استخلاص وخلق التصنيف
يمكن أن يساعد Shaip في استخراج التصنيف وخلقه. يتضمن ذلك تصنيف البيانات وتصنيفها إلى تنسيق منظم يعكس العلاقات بين نقاط البيانات المختلفة. يمكن أن يكون هذا مفيدًا بشكل خاص للشركات في تنظيم بياناتها ، مما يسهل الوصول إليها وتحليلها. على سبيل المثال ، في مجال التجارة الإلكترونية ، يمكن تصنيف بيانات المنتج بناءً على نوع المنتج والعلامة التجارية والسعر وما إلى ذلك ، مما يسهل على العملاء التنقل في كتالوج المنتج.
جمع البيانات
توفر خدمات جمع البيانات لدينا بيانات واقعية أو تركيبية مهمة ضرورية لتدريب خوارزميات الذكاء الاصطناعي التوليدية وتحسين دقة وفعالية نماذجك. البيانات غير متحيزة ، ومصادر أخلاقية ومسؤولة مع الأخذ في الاعتبار خصوصية البيانات وأمنها.

سؤال وجواب
الإجابة على الأسئلة (QA) هي حقل فرعي من معالجة اللغة الطبيعية التي تركز على الإجابة تلقائيًا على الأسئلة في اللغة البشرية. يتم تدريب أنظمة ضمان الجودة على نصوص ورموز شاملة ، مما يمكنها من التعامل مع أنواع مختلفة من الأسئلة ، بما في ذلك الأسئلة الواقعية والتعريفية والقائمة على الرأي. تعد معرفة المجال أمرًا بالغ الأهمية لتطوير نماذج ضمان الجودة المصممة خصيصًا لمجالات محددة مثل دعم العملاء أو الرعاية الصحية أو سلسلة التوريد. ومع ذلك ، تسمح مناهج ضمان الجودة التوليدية للنماذج بإنشاء نص بدون معرفة المجال ، بالاعتماد فقط على السياق.
يمكن لفريق المتخصصين لدينا دراسة المستندات أو الكتيبات الشاملة بدقة لإنشاء أزواج من الأسئلة والإجابات ، مما يسهل إنشاء الذكاء الاصطناعي التوليدي للشركات. يمكن أن يعالج هذا النهج استفسارات المستخدم بشكل فعال عن طريق استخراج المعلومات ذات الصلة من مجموعة واسعة النطاق. يضمن خبراؤنا المعتمدون إنتاج أزواج أسئلة وأجوبة عالية الجودة تمتد عبر مواضيع ومجالات متنوعة.

تلخيص النص
المتخصصون لدينا قادرون على استخلاص محادثات شاملة أو حوارات مطولة ، وتقديم ملخصات موجزة وثاقبة من بيانات نصية واسعة النطاق.

توليد النص
تدريب النماذج باستخدام مجموعة بيانات واسعة من النصوص بأساليب متنوعة ، مثل المقالات الإخبارية والخيال والشعر. يمكن لهذه النماذج بعد ذلك إنشاء أنواع مختلفة من المحتوى ، بما في ذلك المقالات الإخبارية أو إدخالات المدونة أو منشورات الوسائط الاجتماعية ، مما يوفر حلاً فعالاً من حيث التكلفة وموفرًا للوقت لإنشاء المحتوى.
التعرف على الكلام
تطوير نماذج قادرة على فهم اللغة المنطوقة لمختلف التطبيقات. يتضمن ذلك المساعدين الذين يتم تنشيطهم بالصوت وبرامج الإملاء وأدوات الترجمة في الوقت الفعلي. تتضمن العملية استخدام مجموعة بيانات شاملة تتكون من تسجيلات صوتية للغة المنطوقة ، مقترنة بنسخها المقابلة.

توصيات المنتج
طور نماذج باستخدام مجموعات بيانات واسعة من سجلات شراء العملاء ، بما في ذلك الملصقات التي تشير إلى المنتجات التي يميل العملاء إلى شرائها. الهدف هو تقديم اقتراحات دقيقة للعملاء ، وبالتالي زيادة المبيعات وتعزيز رضا العملاء.
شرح الصورة
قم بإحداث ثورة في عملية تفسير الصور الخاصة بك من خلال أحدث خدماتنا لتسميات الصور القائمة على الذكاء الاصطناعي. نبث الحيوية في الصور من خلال إنتاج أوصاف دقيقة وذات مغزى من حيث السياق. يمهد هذا الطريق لإمكانيات تفاعل وتفاعل مبتكرة مع المحتوى المرئي لجمهورك.

تدريب خدمات تحويل النص إلى كلام
نحن نقدم مجموعة بيانات شاملة تتكون من تسجيلات صوتية للكلام البشري ، وهي مثالية لتدريب نماذج الذكاء الاصطناعي. هذه النماذج قادرة على توليد أصوات طبيعية وجذابة لتطبيقاتك ، وبالتالي تقديم تجربة صوتية مميزة وغامرة لمستخدميك.



