
لقد تفاعلنا جميعًا مع تطبيقات الذكاء الاصطناعي للمحادثة مثل Alexa و Siri و Google Home. جعلت هذه التطبيقات حياتنا اليومية أسهل بكثير وأفضل.
يعمل الذكاء الاصطناعي التحادثي على تعزيز مستقبل التكنولوجيا الحديثة وتسهيل التواصل المعزز بين البشر والآلات. عند تصميم مساعد دردشة سلس يعمل بشكل فعال ودقيق ، يجب أن تكون على دراية أيضًا بتحديات التطوير العديدة التي قد تواجهها.
هنا سوف نتحدث عن:
- تحديات البيانات المشتركة المختلفة
- كيف تؤثر هذه على المستهلكين؟
- أفضل الطرق للتغلب على هذه التحديات والمزيد.
تحديات البيانات الشائعة في الذكاء الاصطناعي للمحادثة
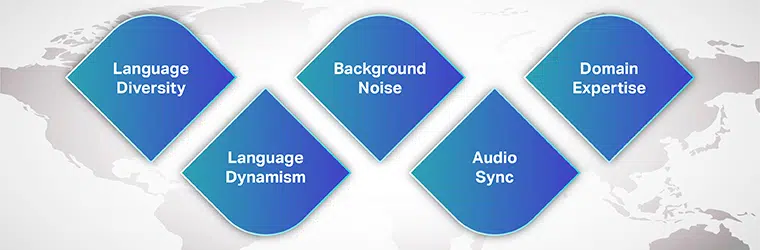
استنادًا إلى خبرتنا في العمل مع كبار العملاء والمشاريع المعقدة ، قمنا بتجميع قائمة من أكثر تحديات بيانات الذكاء الاصطناعي شيوعًا للمحادثة بالنسبة لك.
تنوع اللغات
يعد بناء مساعد دردشة قائم على الذكاء الاصطناعي للمحادثة يمكنه تلبية تنوع اللغات تحديًا كبيرًا.
هناك حوالي 1.35 مليار نسمة الذين يتحدثون الإنجليزية إما كلغة ثانية أو كلغة أصلية. هذا يعني أن أقل من 20٪ من سكان العالم يتحدثون الإنجليزية ، تاركين بقية السكان يتحدثون بلغات أخرى غير الإنجليزية. لذلك ، إذا كنت تقوم بعمل مساعد محادثة محادثة ، فيجب عليك أيضًا مراعاة تنوع عوامل اللغة.
دينامية اللغة
أي لغة ديناميكية ، والتقاط ديناميكيتها وتدريب خوارزمية التعلم الآلي القائمة على الذكاء الاصطناعي ليس بالأمر السهل. اللهجات والنطق واللغة العامية والفروق الدقيقة يمكن أن تؤثر على كفاءة نموذج الذكاء الاصطناعي.
ومع ذلك ، فإن التحدي الأكبر للتطبيق القائم على الذكاء الاصطناعي هو فك شفرة العامل البشري بدقة في مدخلات اللغة. يجلب البشر المشاعر والعواطف في المعركة ، مما يجعل من الصعب على أداة الذكاء الاصطناعي فهمها والتفاعل معها.
ضجيج في الخلفية
يمكن أن تكون ضوضاء الخلفية في المحادثات المتزامنة أو الأصوات المتداخلة الأخرى.
تنظيف مجموعة الصوت الخاصة بك من ضوضاء الخلفية المتداخلة مثل أجراس الباب ، نباح الكلاب أو الأطفال يعد التحدث في الخلفية أمرًا بالغ الأهمية لنجاح التطبيق.
إلى جانب ذلك ، يتعين على تطبيقات الذكاء الاصطناعي هذه الأيام التعامل مع المساعدين الصوتيين المتنافسين الموجودين في نفس المبنى. يصبح من الصعب على المساعد الصوتي التمييز بين الأوامر الصوتية البشرية والمساعدين الصوتيين الآخرين عند حدوث ذلك.
مزامنة الصوت
عند استخراج البيانات من محادثة هاتفية لتدريب المساعد الافتراضي ، من الممكن أن يكون المتصل والوكيل في سطرين مختلفين. من الضروري أن يكون لديك صوتيات من كلا الجانبين لتتم مزامنتها ، والتقاط المحادثات دون الرجوع إلى كل ملف.
نقص البيانات الخاصة بالمجال
يجب أن يعالج التطبيق المستند إلى AI لغة خاصة بالمجال. على الرغم من أن المساعدين الصوتيين يظهرون وعدًا استثنائيًا في معالجة اللغة الطبيعية، لم يثبت بعد هيمنتهم على لغة خاصة بالصناعة. على سبيل المثال ، بشكل عام لن تقدم إجابات للأسئلة الخاصة بالمجال حول صناعات السيارات أو التمويل.
كيف تؤثر هذه التحديات على المستهلكين؟
قد يكون مساعدو الدردشة بالذكاء الاصطناعي للمحادثة مشابهين للبحث المستند إلى النص. لكن يوجد فرق أساسي بين الاثنين. في دعم البحث المستند إلى النص ، يقدم التطبيق قائمة بنتائج البحث ذات الصلة التي يمكن للمستخدم الاختيار من بينها ، مما يمنح المستخدمين المرونة التي هم في أمس الحاجة إليها في اختيار أحد الخيارات.
ومع ذلك ، في الذكاء الاصطناعي للمحادثة ، لا يحصل المستخدمون عمومًا على أكثر من خيار واحد ، ويتوقعون أيضًا أن يقدم التطبيق أفضل نتيجة.
إذا كانت أداة الذكاء الاصطناعي مصحوبة بتحيز في البيانات ، فلن تكون النتيجة بالتأكيد دقيقة أو موثوقة. يمكن أن تتأثر النتائج بالشعبية وليس بمتطلبات المستخدم ، مما يجعل النتيجة زائدة عن الحاجة.
الحل: التغلب على التحديات خلال مرحلة جمع البيانات
ستكون الخطوة الأولى في مكافحة التحيز في التدريب هي الوعي والقبول. بمجرد أن تعرف أن مجموعة البيانات الخاصة بك يمكن أن تكون مليئة بالتحيزات ، فإنك ملزم باتخاذ الإجراءات التصحيحية.
ستكون الخطوة التالية هي توفير عناصر تحكم استباقية للمستخدم لتغيير الإعدادات لتعويض التحيز مباشرة. أو يمكن إرسال التعليقات في النظام للتخفيف من مشكلات التحيز بشكل استباقي.
يتطلب التخفيف من ضوضاء الخلفية والمحادثات المتزامنة والتعامل مع الأشخاص المتعددين تقنيات التعرف على الصوت المحسنة. يجب أيضًا تدريب النظام على فهم المحادثة والكلمات أو العبارات السياقية.
يمكن أيضًا تعزيز القدرة على تحديد الأصوات غير البشرية عند تقديم النظام لمخاطبة الأشخاص غير المسجلين أو الأصوات.
عندما يتعلق الأمر بالتنوع في اللغات ، يكمن الحل في زيادة عدد مجموعات البيانات اللغوية المستخدمة لتدريب النموذج. لذلك ، عندما تزيد الشركات من عدد الأنظمة لتلبية الأسواق اللغوية الكبيرة ، يمكن تحقيق التنوع اللغوي بسلاسة.
فوائد العمل مع البائعين الخارجيين
هناك العديد من الفوائد للعمل مع البائعين الخارجيين لأنها تساعد في التخفيف من بعض تحديات جمع بيانات المحادثة.
يوفر العمل مع البائعين ذوي الخبرة من الجهات الخارجية قدرًا أكبر من الكفاءة والموثوقية من حيث التكلفة. أنها فعالة من حيث التكلفة الحصول على مجموعات بيانات عالية الجودة من بائعين موثوقين بدلاً من الحصول على جمع البيانات من مجموعات بيانات تدريب الذكاء الاصطناعي للمحادثة مفتوحة المصدر.
على الرغم من أن التحيزات لا بد أن تكون موجودة في كل مجموعة بيانات ، إلا أنه مع مورِّد خارجي ، يمكنك تقليل التكلفة المرتبطة بإعادة صياغة النموذج أو إعادة تدريبه بسبب تناقضات البيانات والتحيزات اللغوية المفرطة.
سيساعدك البائع المتمرس أيضًا على توفير الوقت في جمع البيانات وشرح دقيق. سيكون لدى البائع الخارجي الخبرة اللغوية المطلوبة لتطوير نماذج الذكاء الاصطناعي التي يمكن أن تفتح أسواقًا جديدة لعملك.
يمكن للبائع توفير مجموعات بيانات عالية الجودة وقابلة للتخصيص تناسب تفضيلات نموذجك ومتطلباته. لا يمكن أن تعمل جميع حلول جمع البيانات المعبأة مسبقًا والتعليقات التوضيحية لصالحك عند النظر إلى خدمة العملاء المحسنة ، ومعدلات التحويل الأعلى ، وانخفاض تكاليف الأعمال.
لدينا بيانات المحادثة التي يحتاجها نموذج الذكاء الاصطناعي الخاص بك.
كمزود موثوق به وذوي الخبرة ، لدى Shaip مجموعة ضخمة من ملفات مجموعات بيانات AI للمحادثة لجميع أنواع نماذج التعلم الآلي. إلى جانب ذلك ، نحن نقدم أيضًا بيانات محادثة مخصصة بالكامل بالعديد من اللغات واللهجات واللغات العامية. إذا كنت ترغب في تطوير تطبيق دعم دردشة موثوق ودقيق قائم على الذكاء الاصطناعي ، فلدينا جميع الأدوات التي يمكن أن تجعل مشروعك ناجحًا.


