
يستمر الذكاء الاصطناعي والبيانات الضخمة والتعلم الآلي في التأثير على صانعي السياسات والشركات والعلوم والمؤسسات الإعلامية ومجموعة متنوعة من الصناعات في جميع أنحاء العالم. تشير التقارير إلى أن معدل التبني العالمي للذكاء الاصطناعي يبلغ حاليًا 35٪ في 2022 - زيادة هائلة بنسبة 4٪ عن عام 2021. يقال إن 42٪ إضافية من الشركات تستكشف الفوائد العديدة للذكاء الاصطناعي لأعمالها.
دعم العديد من مبادرات الذكاء الاصطناعي و تعلم آلة الحلول هي البيانات. يمكن أن يكون الذكاء الاصطناعي جيدًا مثل البيانات التي تغذي الخوارزمية. قد تؤدي البيانات منخفضة الجودة إلى نتائج منخفضة الجودة وتنبؤات غير دقيقة.
على الرغم من وجود الكثير من الاهتمام لتطوير حلول ML و AI ، إلا أن الوعي بما يمكن اعتباره مجموعة بيانات عالية الجودة مفقود. في هذه المقالة ، نتصفح الجدول الزمني لـ جودة بيانات التدريب على الذكاء الاصطناعي وتحديد مستقبل الذكاء الاصطناعي من خلال فهم جمع البيانات والتدريب.
تعريف بيانات التدريب على الذكاء الاصطناعي
عند بناء حل ML ، فإن كمية ونوعية مجموعة بيانات التدريب مهمة. لا يتطلب نظام ML كميات كبيرة من بيانات التدريب الديناميكية وغير المتحيزة والقيمة فحسب ، بل يحتاج أيضًا إلى الكثير منها.
ولكن ما هي بيانات التدريب على الذكاء الاصطناعي؟
بيانات تدريب الذكاء الاصطناعي عبارة عن مجموعة من البيانات المصنفة المستخدمة لتدريب خوارزمية ML لعمل تنبؤات دقيقة. يحاول نظام ML التعرف على الأنماط وتحديدها ، وفهم العلاقات بين المعلمات ، واتخاذ القرارات اللازمة ، والتقييم بناءً على بيانات التدريب.
خذ على سبيل المثال السيارات ذاتية القيادة. يجب أن تتضمن مجموعة بيانات التدريب الخاصة بنموذج ML ذاتية القيادة صورًا ومقاطع فيديو معنونة للسيارات والمشاة وعلامات الشوارع والمركبات الأخرى.
باختصار ، لتحسين جودة خوارزمية ML ، فإنك تحتاج إلى كميات كبيرة من بيانات التدريب جيدة التنظيم ، والمزودة بتعليقات توضيحية ، وتسمية.
أهمية جودة بيانات التدريب وتطورها
بيانات التدريب عالية الجودة هي المدخلات الرئيسية في تطوير تطبيقات الذكاء الاصطناعي والتعلم الآلي. يتم جمع البيانات من مصادر مختلفة وتقديمها في شكل غير منظم وغير مناسب لأغراض التعلم الآلي. دائمًا ما تكون بيانات التدريب عالية الجودة - الموصوفة والتوضيحية والموسومة - في تنسيق منظم - مثالية لتدريب تعلم الآلة.
تسهل بيانات التدريب عالية الجودة على نظام ML التعرف على الكائنات وتصنيفها وفقًا لميزات محددة مسبقًا. يمكن أن تسفر مجموعة البيانات عن نتائج نموذجية سيئة إذا لم يكن التصنيف دقيقًا.
الأيام الأولى لبيانات تدريب الذكاء الاصطناعي
على الرغم من سيطرة الذكاء الاصطناعي على عالم الأعمال والأبحاث الحالي ، إلا أن الأيام الأولى التي سبقت تعلم التعلم الآلي هيمنت الذكاء الاصطناعي كان مختلفًا تمامًا.
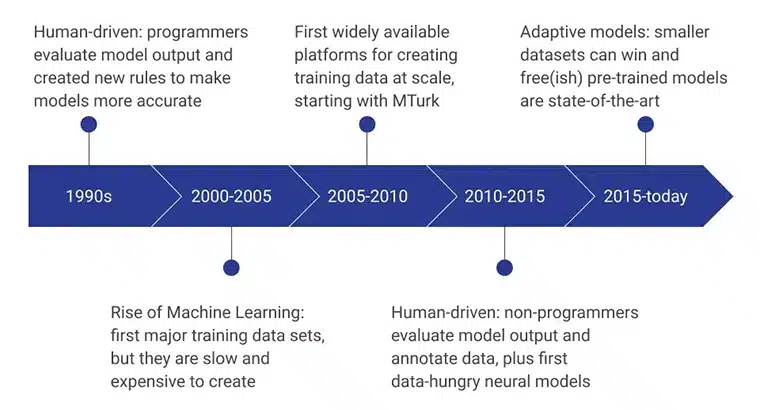
تم تشغيل المراحل الأولية لبيانات التدريب على الذكاء الاصطناعي بواسطة مبرمجين بشريين قاموا بتقييم مخرجات النموذج من خلال ابتكار قواعد جديدة باستمرار جعلت النموذج أكثر كفاءة. في الفترة 2000-2005 ، تم إنشاء أول مجموعة بيانات رئيسية ، وكانت عملية بطيئة للغاية وتعتمد على الموارد ومكلفة. وقد أدى ذلك إلى تطوير مجموعات بيانات تدريبية على نطاق واسع ، ولعبت MTurk من أمازون دورًا مهمًا في تغيير تصورات الناس تجاه جمع البيانات. في الوقت نفسه ، بدأ أيضًا وضع العلامات والتعليقات التوضيحية البشرية.
ركزت السنوات القليلة التالية على قيام غير المبرمجين بإنشاء وتقييم نماذج البيانات. في الوقت الحالي ، ينصب التركيز على النماذج المدربة مسبقًا التي تم تطويرها باستخدام طرق جمع بيانات التدريب المتقدمة.
الكمية تفوق الجودة
عند تقييم سلامة مجموعات بيانات التدريب على الذكاء الاصطناعي في الماضي ، ركز علماء البيانات عليها كمية بيانات تدريب الذكاء الاصطناعي على الجودة.
على سبيل المثال ، كان هناك اعتقاد خاطئ شائع بأن قواعد البيانات الكبيرة تقدم نتائج دقيقة. كان يُعتقد أن الحجم الهائل للبيانات مؤشر جيد لقيمة البيانات. الكمية هي فقط أحد العوامل الأساسية التي تحدد قيمة مجموعة البيانات - تم التعرف على دور جودة البيانات.
الوعي بأن جودة البيانات يعتمد على اكتمال البيانات ، والموثوقية ، والصلاحية ، والتوافر ، والتوقيت. الأهم من ذلك ، أن ملاءمة البيانات للمشروع حددت جودة البيانات التي تم جمعها.
قيود أنظمة الذكاء الاصطناعي المبكرة بسبب ضعف بيانات التدريب
كانت بيانات التدريب السيئة ، إلى جانب الافتقار إلى أنظمة الحوسبة المتقدمة ، أحد أسباب عدم الوفاء بوعود عديدة لأنظمة الذكاء الاصطناعي المبكرة.
نظرًا لعدم وجود بيانات تدريب عالية الجودة ، لم تتمكن حلول ML من تحديد الأنماط المرئية التي تعطل تطوير البحث العصبي بدقة. على الرغم من أن العديد من الباحثين حددوا الوعد بالتعرف على اللغة المنطوقة ، إلا أن البحث أو تطوير أدوات التعرف على الكلام لا يمكن أن يؤتي ثماره بفضل نقص مجموعات بيانات الكلام. كانت العقبة الرئيسية الأخرى أمام تطوير أدوات الذكاء الاصطناعي المتطورة هي افتقار أجهزة الكمبيوتر إلى القدرات الحسابية والتخزينية.
التحول إلى جودة بيانات التدريب
كان هناك تحول ملحوظ في الوعي بأن جودة مجموعة البيانات مهمة. لكي يقوم نظام التعلم الآلي بتقليد الذكاء البشري وقدرات اتخاذ القرار بدقة ، يجب أن يزدهر على بيانات التدريب عالية الجودة وعالية الجودة.
فكر في بيانات ML الخاصة بك على أنها استبيان - كلما زاد حجم عينة البيانات الحجم ، كان التنبؤ أفضل. إذا لم تتضمن بيانات العينة جميع المتغيرات ، فقد لا تتعرف على الأنماط أو تقدم استنتاجات غير دقيقة.
التطورات في تكنولوجيا الذكاء الاصطناعي والحاجة إلى بيانات تدريب أفضل
 تؤدي التطورات في تقنية الذكاء الاصطناعي إلى زيادة الحاجة إلى بيانات تدريب عالية الجودة.
تؤدي التطورات في تقنية الذكاء الاصطناعي إلى زيادة الحاجة إلى بيانات تدريب عالية الجودة.أدى فهم أن بيانات التدريب الأفضل تزيد من فرصة نماذج تعلم الآلة الموثوقة إلى تحسين منهجيات جمع البيانات والتعليقات التوضيحية ووضع العلامات. أثرت جودة البيانات وملاءمتها بشكل مباشر على جودة نموذج الذكاء الاصطناعي.
 تؤدي التطورات في تقنية الذكاء الاصطناعي إلى زيادة الحاجة إلى بيانات تدريب عالية الجودة.
تؤدي التطورات في تقنية الذكاء الاصطناعي إلى زيادة الحاجة إلى بيانات تدريب عالية الجودة.زيادة التركيز على جودة البيانات ودقتها
لكي يبدأ نموذج ML في تقديم نتائج دقيقة ، يتم تغذيته على مجموعات بيانات عالية الجودة تمر عبر خطوات تنقيح البيانات التكرارية.
على سبيل المثال ، قد يكون الإنسان قادرًا على التعرف على سلالة معينة من الكلاب في غضون أيام قليلة بعد تقديمه إلى السلالة - من خلال الصور أو مقاطع الفيديو أو شخصيًا. يستمد البشر من خبراتهم والمعلومات ذات الصلة لتذكر واستخراج هذه المعرفة عند الضرورة. ومع ذلك ، فهي لا تعمل بسهولة مع آلة. يجب تغذية الماكينة بصور مشروحة ومُعينة بوضوح - مئات أو آلاف - من تلك السلالة المعينة والسلالات الأخرى حتى يتسنى لها إجراء الاتصال.
يتنبأ نموذج الذكاء الاصطناعي بالنتيجة من خلال ربط المعلومات المدربة بالمعلومات المقدمة في العالم الحقيقي. تصبح الخوارزمية عديمة الفائدة إذا لم تتضمن بيانات التدريب المعلومات ذات الصلة.
أهمية بيانات التدريب المتنوعة والتمثيلية
يؤدي تنوع البيانات المتزايد أيضًا إلى زيادة الكفاءة وتقليل التحيز وتعزيز التمثيل العادل لجميع السيناريوهات. إذا تم تدريب نموذج الذكاء الاصطناعي باستخدام مجموعة بيانات متجانسة ، فيمكنك التأكد من أن التطبيق الجديد سيعمل فقط لغرض معين ويخدم مجموعة سكانية معينة.يمكن أن تكون مجموعة البيانات متحيزة تجاه مجموعة معينة من السكان والعرق والجنس والاختيار والآراء الفكرية ، مما قد يؤدي إلى نموذج غير دقيق.
من المهم التأكد من أن تدفق عملية جمع البيانات بالكامل ، بما في ذلك اختيار مجموعة الموضوعات ، والتنظيم ، والتعليق التوضيحي ، والتسمية ، متنوع بشكل كاف ومتوازن وممثل للسكان.
 يؤدي تنوع البيانات المتزايد أيضًا إلى زيادة الكفاءة وتقليل التحيز وتعزيز التمثيل العادل لجميع السيناريوهات. إذا تم تدريب نموذج الذكاء الاصطناعي باستخدام مجموعة بيانات متجانسة ، فيمكنك التأكد من أن التطبيق الجديد سيعمل فقط لغرض معين ويخدم مجموعة سكانية معينة.
يؤدي تنوع البيانات المتزايد أيضًا إلى زيادة الكفاءة وتقليل التحيز وتعزيز التمثيل العادل لجميع السيناريوهات. إذا تم تدريب نموذج الذكاء الاصطناعي باستخدام مجموعة بيانات متجانسة ، فيمكنك التأكد من أن التطبيق الجديد سيعمل فقط لغرض معين ويخدم مجموعة سكانية معينة.مستقبل بيانات التدريب على الذكاء الاصطناعي
يتوقف النجاح المستقبلي لنماذج الذكاء الاصطناعي على جودة وكمية بيانات التدريب المستخدمة لتدريب خوارزميات التعلم الآلي. من الأهمية بمكان إدراك أن هذه العلاقة بين جودة البيانات وكميتها خاصة بالمهمة وليس لها إجابة محددة.
في النهاية ، يتم تحديد كفاية مجموعة بيانات التدريب من خلال قدرتها على الأداء الجيد بشكل موثوق للغرض الذي تم إنشاؤه.
التقدم في جمع البيانات وتقنيات التعليق التوضيحي
نظرًا لأن ML حساس للبيانات التي تم تغذيتها ، فمن الضروري تبسيط سياسات جمع البيانات والتعليقات التوضيحية. تساهم الأخطاء في جمع البيانات ، ومعالجتها ، والتحريف ، والقياسات غير المكتملة ، والمحتوى غير الدقيق ، وتكرار البيانات ، والقياسات الخاطئة في عدم كفاية جودة البيانات.
يمهد جمع البيانات الآلي من خلال التنقيب عن البيانات وكشط الويب واستخراج البيانات الطريق لتوليد البيانات بشكل أسرع. بالإضافة إلى ذلك ، تعمل مجموعات البيانات المعبأة مسبقًا كتقنية تجميع بيانات سريعة الإصلاح.
التعهيد الجماعي هو طريقة أخرى رائدة في جمع البيانات. بينما لا يمكن ضمان صحة البيانات ، فهي أداة ممتازة لجمع الصورة العامة. أخيرًا ، متخصص جمع البيانات يوفر الخبراء أيضًا بيانات تم الحصول عليها لأغراض محددة.
زيادة التركيز على الاعتبارات الأخلاقية في بيانات التدريب
مع التقدم السريع في الذكاء الاصطناعي ، ظهرت العديد من القضايا الأخلاقية ، لا سيما في مجال جمع بيانات التدريب. تتضمن بعض الاعتبارات الأخلاقية في جمع بيانات التدريب الموافقة المستنيرة والشفافية والتحيز وخصوصية البيانات.نظرًا لأن البيانات تتضمن الآن كل شيء بدءًا من صور الوجه وبصمات الأصابع والتسجيلات الصوتية وغيرها من البيانات الحيوية الهامة ، فقد أصبح من المهم للغاية ضمان الالتزام بالممارسات القانونية والأخلاقية لتجنب الدعاوى القضائية الباهظة والإضرار بالسمعة.
إمكانية الحصول على بيانات تدريب متنوعة وجودة أفضل في المستقبل
هناك إمكانات هائلة ل بيانات تدريبية عالية الجودة ومتنوعة فى المستقبل. بفضل الوعي بجودة البيانات وتوافر مزودي البيانات الذين يلبيون متطلبات الجودة لحلول الذكاء الاصطناعي.
إن موفري البيانات الحاليين بارعون في استخدام التقنيات الرائدة للحصول على كميات هائلة من مجموعات البيانات المتنوعة بشكل أخلاقي وقانوني. لديهم أيضًا فرق داخلية لتصنيف البيانات المخصصة لمشاريع تعلم الآلة المختلفة والتعليق عليها وتقديمها.
 مع التقدم السريع في الذكاء الاصطناعي ، ظهرت العديد من القضايا الأخلاقية ، لا سيما في مجال جمع بيانات التدريب. تتضمن بعض الاعتبارات الأخلاقية في جمع بيانات التدريب الموافقة المستنيرة والشفافية والتحيز وخصوصية البيانات.
مع التقدم السريع في الذكاء الاصطناعي ، ظهرت العديد من القضايا الأخلاقية ، لا سيما في مجال جمع بيانات التدريب. تتضمن بعض الاعتبارات الأخلاقية في جمع بيانات التدريب الموافقة المستنيرة والشفافية والتحيز وخصوصية البيانات.وفي الختام
من المهم أن تتعاون مع بائعين موثوقين لديهم فهم عميق للبيانات والجودة تطوير نماذج عالية الجودة للذكاء الاصطناعي. Shaip هي شركة التعليقات التوضيحية الأولى الماهرة في توفير حلول بيانات مخصصة تلبي احتياجات وأهداف مشروع الذكاء الاصطناعي الخاص بك. شارك معنا واستكشف الكفاءات والالتزام والتعاون التي نضعها على طاولة المفاوضات.


